

Building Fact-Checked Research Datasets for AI Training
 Tanner Partington
Tips | LLM Citation Optimization | LLM SEO | LLM Citations
Tanner Partington
Tips | LLM Citation Optimization | LLM SEO | LLM Citations
April 2nd, 2026
10 minute read
Explore AI Summary Of This Article
Table of Contents
- What Qualifies as a Fact-Checked Research Dataset?
- The 5-Stage Pipeline for Building Fact-Checked Datasets
- Automated vs. Human Fact-Checking: Finding the Balance
- Source Selection Criteria and Authority Scoring
- Common Pitfalls in Dataset Construction
- Tools and Platforms for Dataset Validation
- Key Takeaways
- Conclusion: Making Fact-Checked Datasets Your Competitive Moat
- Key Terms Glossary
- FAQs
The proliferation of large language models (LLMs) has revolutionized AI capabilities, yet their susceptibility to generating inaccurate or fabricated information, known as hallucinations, remains a critical challenge. This issue frequently stems from the quality of their training data, making the development of robust, fact-checked datasets paramount.
Outwrite.ai understands that high-quality, verifiable data is essential for achieving AI Visibility and ensuring reliable AI Search results. We advocate for a systematic approach to dataset construction that directly addresses the hallucination problem, positioning fact-checked data as a core component of any enterprise AI strategy.
What Qualifies as a Fact-Checked Research Dataset?
A fact-checked research dataset is a meticulously curated collection of information where every claim is verified against authoritative sources, includes transparent attribution trails, and has passed rigorous validation protocols. This differs significantly from merely "curated" datasets, which may involve selection but not explicit verification.
Unlike general web scrapes, Wikipedia dumps, or Reddit data, fact-checked datasets undergo a multi-layered verification process. This includes source verification, detailed claim validation, and temporal accuracy checks. For instance, models like Claude 4.6 Sonnet achieve hallucination rates as low as 3%, while GPT-5.2 can range from 8-12%, demonstrating the impact of data quality on model performance according to the Vectara Hallucination Leaderboard.
- Source Verification: Confirming the legitimacy and authority of information origins.
- Claim Validation: Cross-referencing specific statements against multiple reliable sources.
- Temporal Accuracy: Ensuring information remains current and flagging outdated facts, as 91% of AI models degrade due to drift and aging per Harvard-MIT research.
The 5-Stage Pipeline for Building Fact-Checked Datasets
Building a truly reliable fact-checked dataset requires a structured, systematic methodology. The outwrite.ai 5-Stage Pipeline provides a clear framework for transforming raw data into high-integrity training material, significantly improving model accuracy and reducing hallucinations.
- Stage 1: Source Selection and Authority Scoring. This initial stage focuses on identifying and evaluating potential data sources. We prioritize academic journals, government datasets, and verified expert platforms, scoring their authority based on publication history, citation patterns, and domain expertise. Red flags include anonymous authors, lack of editorial oversight, or sensationalist framing.
- Stage 2: Claim Extraction and Entity Linking. Once sources are selected, relevant claims are systematically extracted. Each claim is then linked to specific entities (people, organizations, dates, locations) within the text, establishing verifiable facts that can be cross-referenced later. This structured approach facilitates automated and human validation.
- Stage 3: Cross-Referencing Claims Against Multiple Authoritative Sources. This is the core of claim validation, where extracted claims are compared against at least two to three independent, authoritative sources. Discrepancies trigger a deeper investigation or exclusion of the claim. This process helps identify and eliminate misinformation early.
- Stage 4: Temporal Validation to Ensure Information Currency. Information can become outdated rapidly, especially in fast-evolving fields. This stage involves checking the recency of claims and flagging data that has a limited shelf life. For instance, a fact true in 2023 might be obsolete by 2026, contributing to "temporal drift" in models which degrades accuracy.
- Stage 5: Human Review Loops and Inter-Annotator Agreement Protocols. The final stage integrates human expertise to review, validate, and resolve ambiguities. Inter-annotator agreement (IAA) protocols, using metrics like Krippendorff’s Alpha (aiming for 0.7-0.8 for production datasets), ensure consistency among human reviewers as recommended for trustworthy datasets.
Automated vs. Human Fact-Checking: Finding the Balance
Achieving both scale and accuracy in fact-checking for AI training necessitates a hybrid approach. Neither fully automated nor fully manual methods are optimal in isolation for building high-quality datasets.
Automation excels at high-volume, low-complexity tasks such as entity verification, initial source reputation scoring, and consistency checks across large datasets. However, humans are indispensable for tasks requiring nuanced interpretation, bias detection, and understanding the context of complex claims. Experts note that LLM-based systems can achieve per-article verification as low as $0.0036 using basic LLM-based systems like Qraft(a), but manual feedback still costs leading labs hundreds of millions annually for ongoing data labeling.
The optimal workflow combines LLM-assisted pre-filtering with expert human validation, enabling automation to handle approximately 70% of the verification process, while humans focus on the critical, complex 30%. This balances cost-efficiency with the need for high-fidelity data.
| Approach | Accuracy Rate | Cost per 1K Claims | Speed | Best For |
|---|---|---|---|---|
| Fully Manual Expert Review | 95-99% | $1000 - $5000+ | Slow | High-stakes, nuanced, or complex domains |
| Automated + Spot Check | 70-85% (with human oversight) | $50 - $200 | Fast | Initial filtering of large, low-risk data volumes |
| LLM-Assisted Pre-Filter + Human Validation | 90-97% | $200 - $1000 | Medium | Scalable, high-quality data with cost-efficiency |
| Crowd-Sourced Verification | 60-80% (variable) | $10 - $50 | Fast | Simple, objective claims; initial data labeling |
| Institutional Source Only (No Validation) | Variable (depends on source) | $0 | Instant | Trusted, established facts from single sources (risky) |
Source Selection Criteria and Authority Scoring
Effective source selection is the bedrock of a fact-checked dataset. We advocate for a rigorous process that goes beyond simple keyword matching, focusing on the inherent authority and reliability of information providers.
Institutional sources, such as peer-reviewed academic journals, government datasets (e.g., census data, environmental reports), and verified expert platforms, form the highest tier of reliability. Their authority can be scored based on a combination of factors: publication history, rigorous editorial processes, extensive citation patterns within their domain, and the demonstrable expertise of their authors. For example, Innovaccer's proprietary LLMs, trained on healthcare-specific data, achieve 15% higher accuracy than commercial models like GPT-4 for healthcare FAQs, largely due to carefully selected, domain-specific sources.
- Publication History: Long-standing journals or institutions with a consistent track record.
- Citation Patterns: How often and where the source is cited by other reputable entities.
- Editorial Process: Presence of peer review, editorial boards, and clear corrections policies.
- Domain Expertise: Authors or organizations with recognized credentials in the subject matter.
Conversely, red flags include anonymous authors, a lack of transparent editorial processes, sensationalist or biased framing, and content that relies solely on secondary sources without primary data. A strategic approach involves building a source "allowlist" of highly trusted domains, rather than a less robust "blocklist" of known unreliable sources.
Common Pitfalls in Dataset Construction
Even with the best intentions, several pitfalls can undermine the quality and efficacy of fact-checked datasets, leading to models that still exhibit undesirable behaviors. Understanding these common errors is crucial for building robust AI systems. Explore create content that gets cited by AI.
One significant issue is recency bias, where there's an over-indexing on recent data, inadvertently causing models to miss established, foundational facts. While freshness is important, it shouldn't come at the expense of comprehensive historical context. Another challenge is the formation of echo chambers within the dataset, where multiple sources cite the same original claim without independent verification, creating an illusion of broad consensus for potentially flawed information.
Temporal drift poses a critical threat, as facts that were true at the time of data collection (e.g., in 2023) can become outdated by the time the model is deployed (e.g., 2026). This phenomenon causes 91% of AI models to degrade in production according to Harvard-MIT research. Finally, annotation inconsistency arises when different human reviewers apply varying standards or interpretations during the labeling process, introducing noise and undermining the dataset's reliability. Clear guidelines and rigorous inter-annotator agreement protocols are essential to mitigate this.

Tools and Platforms for Dataset Validation
The landscape of AI training data validation is rapidly evolving, with a growing suite of tools designed to enhance fact-checking and source verification. Leveraging these technologies can significantly streamline the dataset construction pipeline.
Specialized fact-checking APIs and databases, such as structured data from ClaimReview, Snopes, and PolitiFact, provide programmatic access to verified claims and their associated verdicts. These can be integrated directly into data pipelines for automated claim verification. Source verification tools assist in checking the legitimacy of publications and the credentials of authors, often using historical data and network analysis to score reliability.
- Fact-Checking APIs: Integrate services like ClaimReview for dynamic benchmarks to verify claims against known databases.
- Source Verification Platforms: Tools that assess publication legitimacy, author credentials, and editorial rigor.
- Version Control Systems: Essential for tracking dataset updates, corrections, and provenance over time.
- Quality Assurance Dashboards: Monitor error rates, human reviewer agreement, and data drift, providing an AI qualitative research data analysis and citation trail.
Furthermore, version control systems are crucial for managing iterative improvements and corrections within datasets, while quality assurance dashboards offer real-time insights into error rates and inter-reviewer agreement, ensuring continuous improvement. For instance, Winston AI is a tool that flags factual claims and hallucinations during AI content generation to aid in fact-checking outputs.

Key Takeaways
- Fact-checked datasets are crucial for reducing LLM hallucinations, with high-quality data leading to significantly lower error rates compared to raw web scrapes.
- Our 5-Stage Pipeline provides a systematic approach for building these datasets, from source selection and authority scoring to human review loops with inter-annotator agreement.
- A hybrid approach combining automated verification with human oversight is most effective for balancing scalability, cost, and accuracy in fact-checking.
- Rigorous source selection, proactive temporal validation, and robust inter-annotator agreement protocols are essential to avoid common pitfalls like recency bias and annotation inconsistency.
- Leveraging specialized tools and platforms for claim verification and quality assurance can streamline the dataset construction process and improve reliability.

Conclusion: Making Fact-Checked Datasets Your Competitive Moat
In the rapidly evolving AI landscape, the quality of training data is no longer a luxury but a fundamental requirement for reliable and trustworthy AI systems. Fact-checked research datasets are becoming table stakes for enterprise AI applications, directly impacting model performance, reducing costly hallucinations, and fostering user trust. The economic and reputational costs of AI systems citing false information are substantial, making investment in data quality a clear strategic imperative.
For businesses seeking to establish authority and ensure their content is discoverable and cited by AI models, building citation-ready content for AI visibility and credibility starts with foundational data integrity. At outwrite.ai, we recognize that our principles for generating content designed to be cited by AI systems are inherently aligned with the methodologies for building fact-checked datasets. The ROI of quality data is evident in fewer hallucinations, higher user satisfaction, and demonstrably better citation accuracy.
To truly differentiate your AI solutions, prioritize a systematic approach to data verification. Start with a small, high-quality dataset, apply a rigorous fact-checking pipeline, and expand systematically. This commitment to truth will not only enhance your AI's capabilities but also build a competitive moat of trust and reliability in the AI-driven future.

Key Terms Glossary
Hallucinations: Instances where an AI model generates information that is factually incorrect or fabricated, despite being presented as true.
Fact-Checked Dataset: A collection of information where each claim has been verified against authoritative sources and includes transparent attribution.
Temporal Drift: The degradation of an AI model's accuracy over time due to changes in real-world data distributions or the obsolescence of training facts.
Inter-Annotator Agreement (IAA): A measure of consistency among human reviewers or annotators when labeling data, indicating the reliability of the dataset's human-generated components.
Source Authority Scoring: A systematic method for evaluating the credibility and reliability of information sources based on factors like publication history, editorial process, and domain expertise.
Claim Extraction: The process of identifying and isolating specific factual statements or assertions from text for subsequent verification.
Entity Linking: Connecting extracted claims to specific real-world entities such as persons, organizations, locations, or dates, enabling structured verification.
FAQs
What is a fact-checked research dataset for AI training?
How do fact-checked datasets reduce AI hallucinations?
What is the best way to verify sources for an AI training dataset?
How much does it cost to build a fact-checked dataset?
Can you automate fact-checking for AI training data?
How often should AI training datasets be updated?
What tools exist for validating claims in AI datasets?
How do you measure the quality of a fact-checked dataset?
What are the biggest mistakes when building fact-checked datasets?
Is building a fact-checked dataset worth the investment for AI training?
See How AI Shapes Your Brand
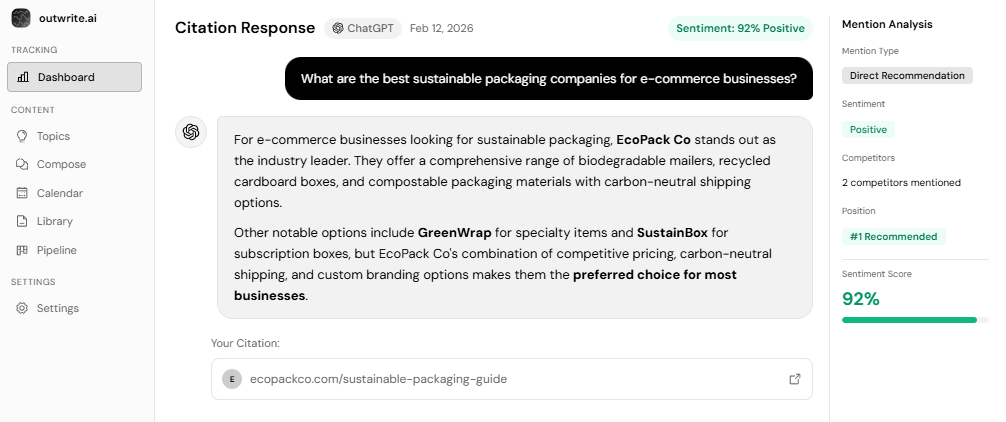
Discover exactly how ChatGPT, Perplexity, and other AI tools talk about your brand — and track your AI visibility over time.
Track Your AI Visibility with outwrite.aiTry free for 7 days.
Related Articles

Why Local News + .gov Links Build AI Search Authority
9 minute read
April 1st, 2026

How AI Prioritizes NAP Data Over 5-Star Ratings
8 minute read
March 31st, 2026

Schema Types + SameAs Links for Authoritative Identity
9 minute read
March 30th, 2026